Abstract
TAO is a federated dataset for Tracking Any Object, containing 2,907 high resolution videos, captured in diverse environments, which are half a minute long on average.
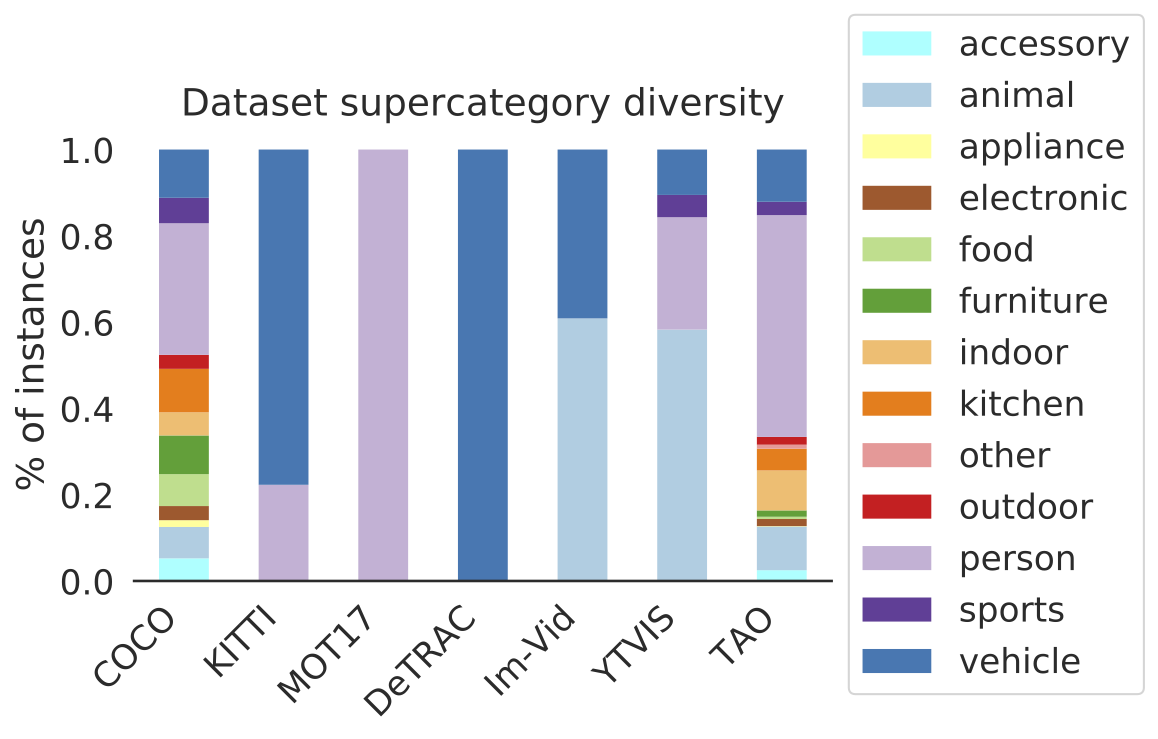
We adopt a bottom-up approach for discovering a large vocabulary of 833 categories, an order of magnitude more than prior tracking benchmarks.
To this end, we ask annotators to label tracks for objects that move at any point in the video, and give names to them post factum.
Our vocabulary is both significantly larger and qualitatively different from existing tracking datasets.
To ensure scalability of annotation, we employ a federated approach that focuses manual effort on labeling tracks for those relevant objects in a video (e.g., those that move).
We perform an extensive evaluation of state-of-the-art tracking methods and make a number of important discoveries regarding large-vocabulary tracking in an open-world.
In particular, we show that existing single- and multi-object trackers struggle when applied to this scenario, and that detection-based, multi-object trackers are in fact competitive with user-initialized ones.
We hope that our dataset and analysis will boost further progress in the tracking community.
Acknowledgements
We thank Jonathon Luiten and Ross Girshick for detailed feedback on the dataset and manuscript, and Nadine Chang and Kenneth Marino for reviewing early drafts. Annotations for this dataset were provided by Scale.ai.
Finally, TAO would not have been possible without the data collection efforts behind
Charades,
LaSOT,
ArgoVerse,
AVA,
YFCC100M,
BDD-100K,
and HACS.
This work was supported in part by the CMU Argo AI Center for Autonomous
Vehicle Research, the Inria associate team GAYA, and by the Intelligence
Advanced Research Projects Activity (IARPA) via Department of
Interior/Interior Business Center (DOI/IBC) contract number D17PC00345.
The U.S. Government is authorized to reproduce and distribute reprints for
Governmental purposes not withstanding any copyright annotation theron.
Disclaimer: The views and conclusions contained herein are those of the
authors and should not be interpreted as necessarily representing the
official policies or endorsements, either expressed or implied of IARPA,
DOI/IBC or the U.S. Government.